2021. 12. 21. 20:25ㆍData Crawling
[ Data Crawling ]
이번 포스팅은 Data 수집 방법인 웹 크롤링에 대해서 포스팅을 할 것이고,
많은 웹 크롤링 방법중 Selenium을 활용하여 데이터 수집하는 방법에 대해서 포스팅을 하겠습니다.
Selenium은 동적인 웹 페이지 크롤링이나 브라우저를 이용한 웹페이지 제어를 할 수 있게 해주는 라이브러리 입니다.
[ 설치 ]
우선 아래 pip를 활용하여 selenium을 설치해 줍니다
pip install selenium
pip install chromedriver-autoinstaller추가로 chromedriver-autoinstaller library를 추가로 설치하는 이유는,
selenium은 browser driver를 이용해야 웹 크롤링을 할 수 있습니다. 만약, Chrome을 이용할 경우 Chrome 버전에 맞는 Chrome driver를 설치해야 Selenium을 이용할 수 있습니다.
chrome 버전이 업데이트 될 때 마다, 매번 driver를 설치해주기 힘듦으로 그 문제를 해결하기 위해, chromedriver-autoinstaller를 설치 해줍니다.
[ 코드 ]
필요한 라이브러리를 호출합니다.
import chromedriver_autoinstaller # chrome driver 자동 설치 라이브러리
from selenium import webdriver데이터 크롤링에 이용될 브라우저를 세팅해줍니다.
# chrome driver를 자동으로 설치함
chromedriver_autoinstaller.install()
options = webdriver.ChromeOptions() # Browser 세팅하기
options.add_argument('lang=ko_KR') # 사용언어 한국어
options.add_argument('disable-gpu') # 하드웨어 가속 안함
# options.add_argument('headless') # 창 숨기기
# 브라우저 세팅
driver = webdriver.Chrome(options=options)세팅된 브라우저에 설저오딘 URL을 호출해줍니다.
# 브라우저에 URL 호출하기
driver.get(url='https://www.naver.com/')아래는 크롤링이 끝나면, 탭이 필요없거나, 종료할때 아래 코드를 입력하여 종료해줍니다.
# 브라우저 탭 닫기
driver.close()
# 브라우저 종료하기 (탭 모두 종료)
driver.quit()[ 결과 ]
아래 결과 이미지를 보시면, [Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다.] 라는 문구가 뜨며, 자동 제어가 되고 있다는걸 알 수 있습니다.
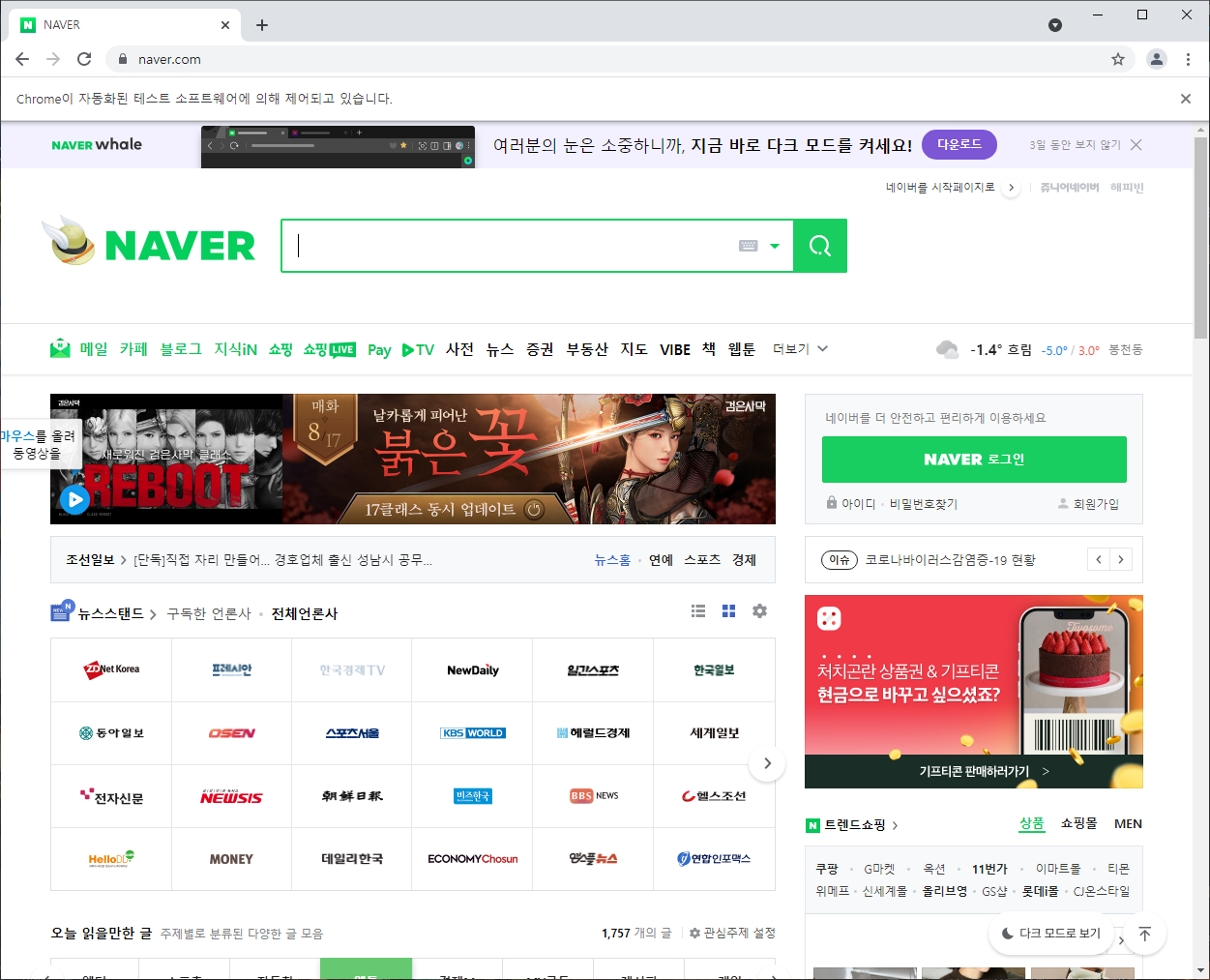
이상 포스팅을 마치겠습니다.
[ 완성된 코드 ]
https://github.com/Mr-DooSun/Selenium-WebCrawling/blob/main/Ex1_browser/ex1_browser.py
GitHub - Mr-DooSun/Selenium-WebCrawling
Contribute to Mr-DooSun/Selenium-WebCrawling development by creating an account on GitHub.
github.com